SQL
Airsequel's SQL workbench lets you execute arbitrary SQL queries on your SQLite database.
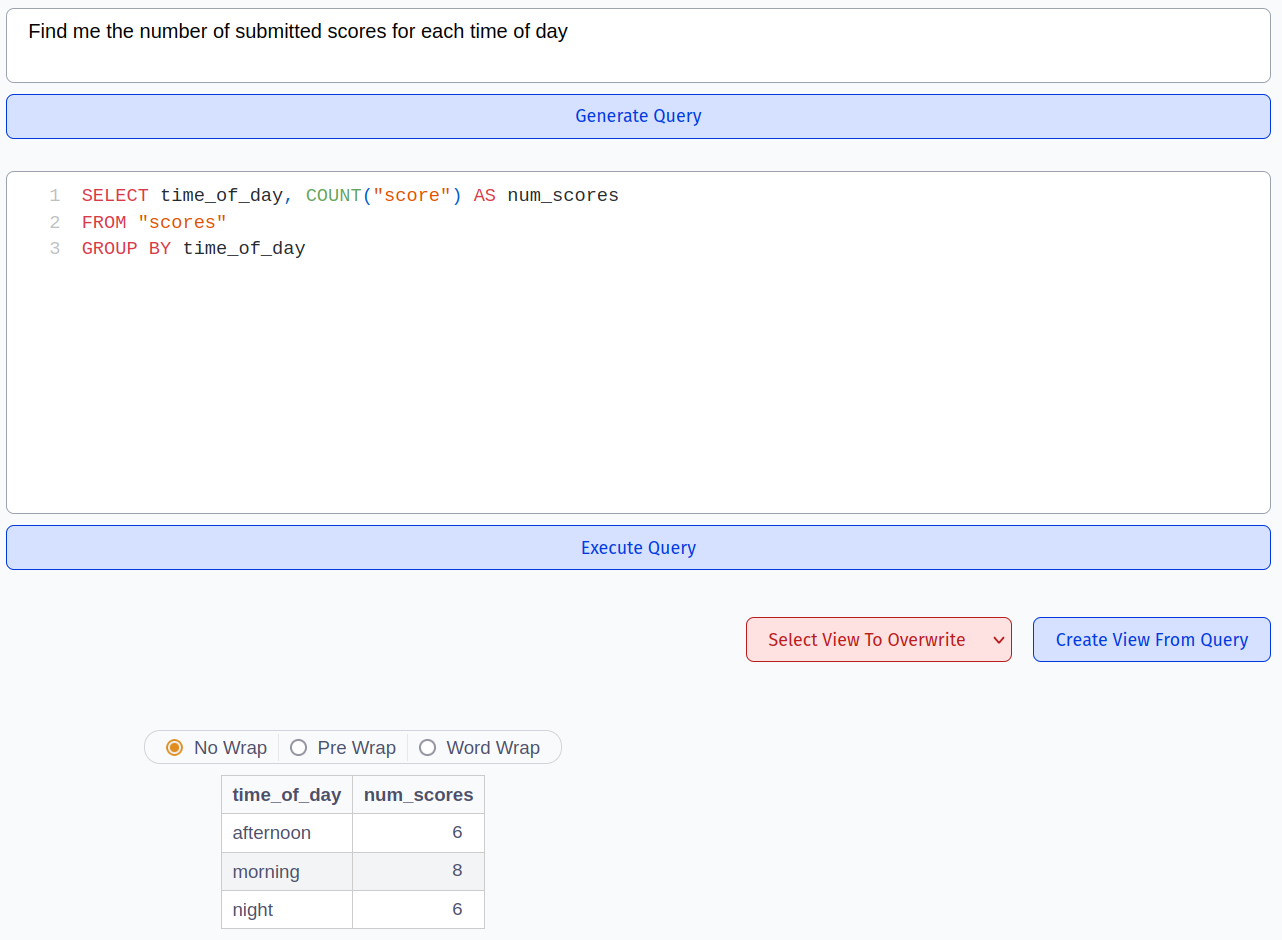
As seen in the screenshot above, airsequel provides OpenAI integration for query generation. Moreover, you can work on multiple queries simultaneously by creating multiple tabs:
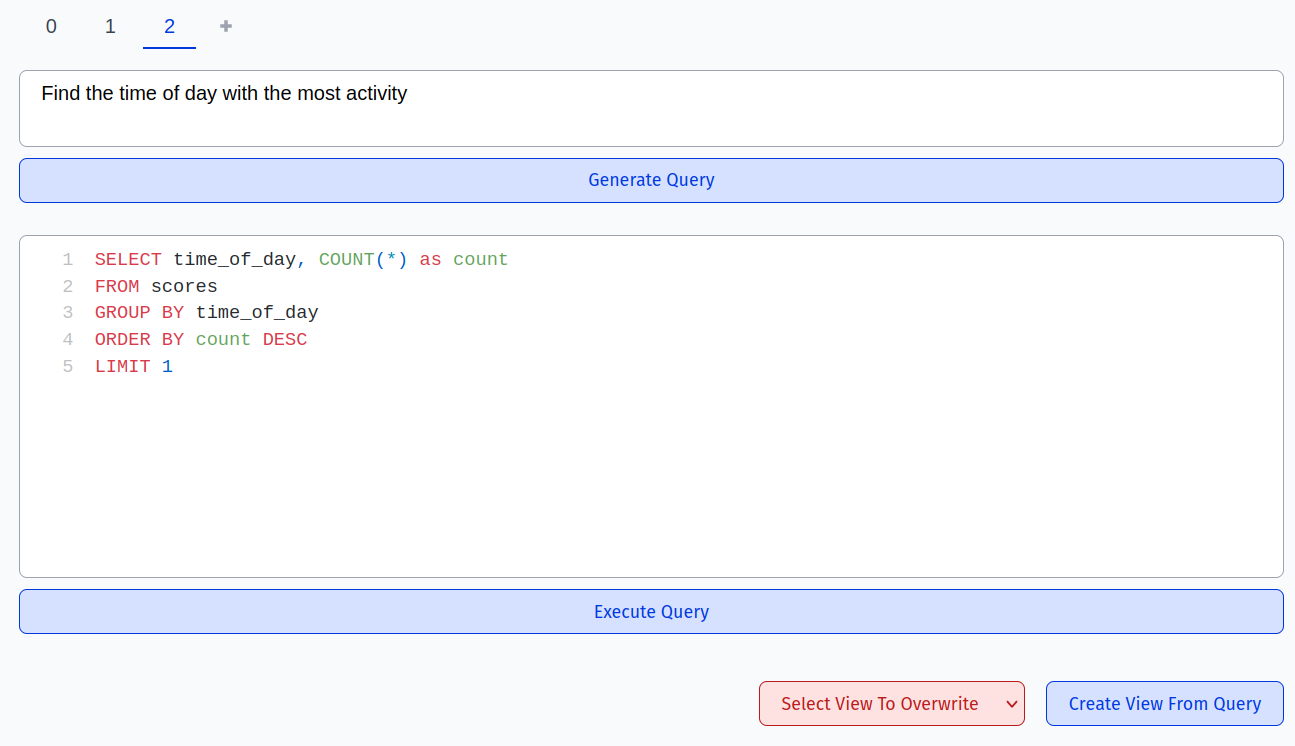
As seen in the pictures above, the query can be saved as a new or existing view using the buttons on the bottom right. By default, the view will now appear in the “tables” tab, but a special “views” tab can be enabled in the settings:
Check out the pricing page for all limitations of the Free edition.
Extra Types for SQLite
In order to support more elaborate types than just the basic SQL types, we came up with a specification on how to extend SQLite with extra datatypes in a standard conformant way.
The basic idea is to use suffixes like e.g. TEXT_EMAIL to specify more refined types. Since SQLite's type affinity will treat this as a TEXT column, it works in a backwards compatible way.
For more details check out the full specification in following repo: https://github.com/Airsequel/SQLite-Extra-Types
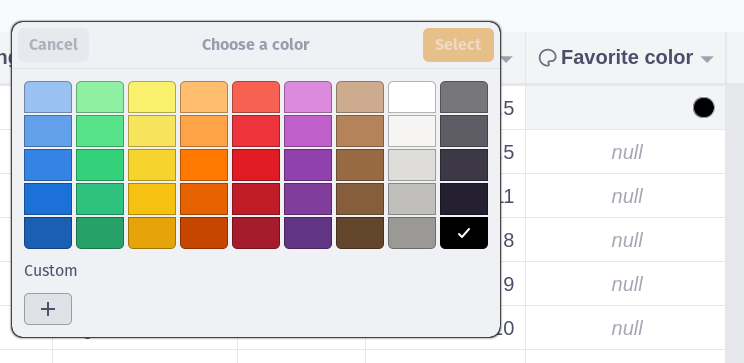
When editing entries via the GUI, Airsequel will provide specialized input fields for the given type. For instance, “color” columns can be edited using a color picker:
Interactive Editing
Airsequel provides comprehensive interactive editing capabilities. The most common operations are presented in the list below:
- Change the name or description of a database
The name and description for a database can be changed by clicking on the respective “edit” icon in the “Database” tab:
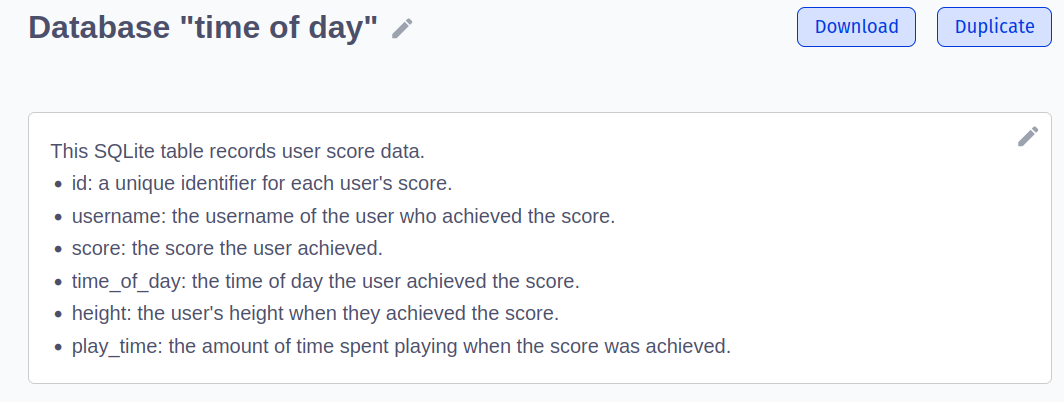 Furthermore, the description can be automatically generated using the built in OpenAI integration:
Furthermore, the description can be automatically generated using the built in OpenAI integration:
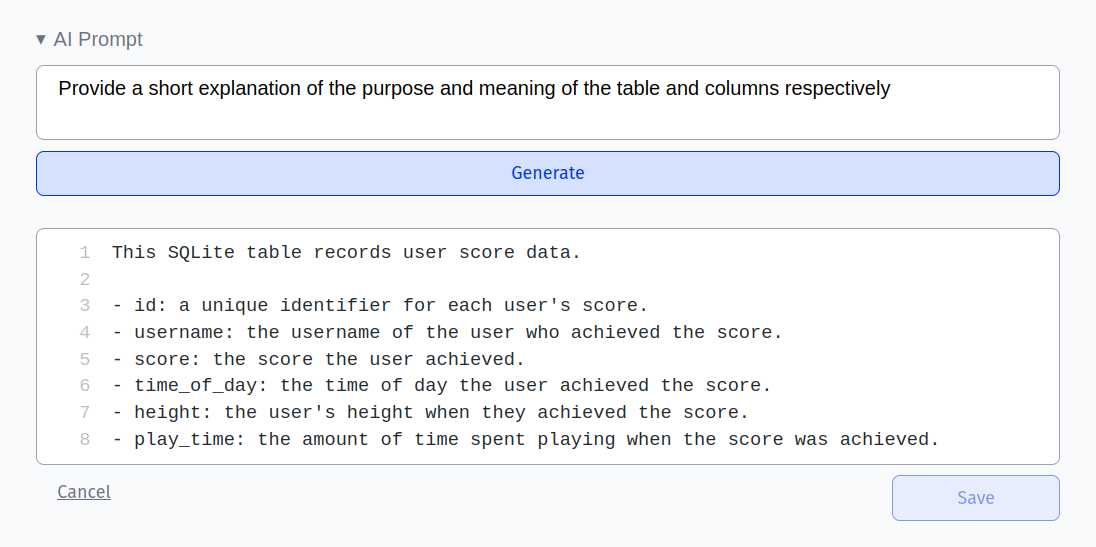 Database descriptions can make use of certain markdown features (italic and bold text, lists, links, headings, …):
Database descriptions can make use of certain markdown features (italic and bold text, lists, links, headings, …):

- Create a table
New tables can be created by using the “+” to the right of the list of existing tables from the tables tab:
- Rename / Delete / Export a table
Click on the arrow next to the name of the table in the “tables” tab:
- Change table description
Click on the arrow next to the name of the table in the “tables” tab.
Airsequel also provides OpenAI integration for generating table descriptions:
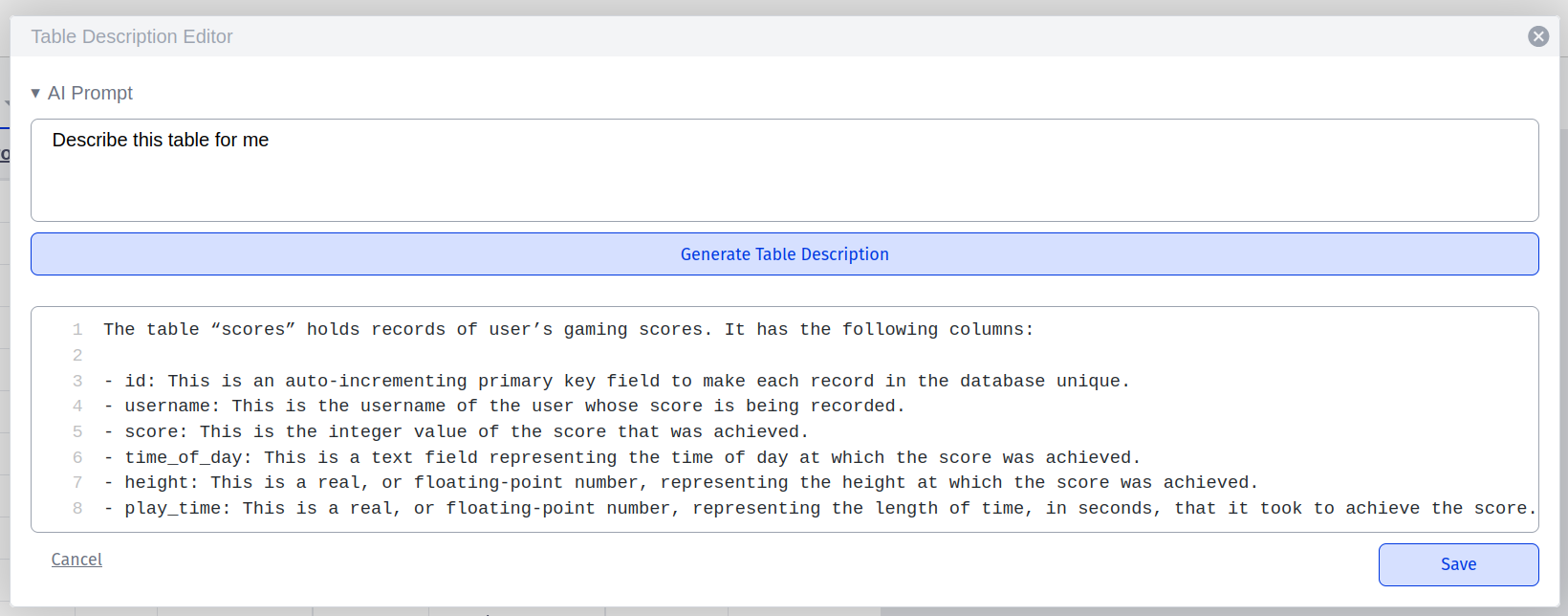
- Create a column
Click on the “+” icon at the end of the list of columns on one of the tables in the “tables” tab:
 Alternatively, columns can be created at arbitrary positions by clicking on the arrow icon next to an existing column and choosing “insert left/right”:
Alternatively, columns can be created at arbitrary positions by clicking on the arrow icon next to an existing column and choosing “insert left/right”:
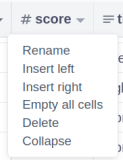
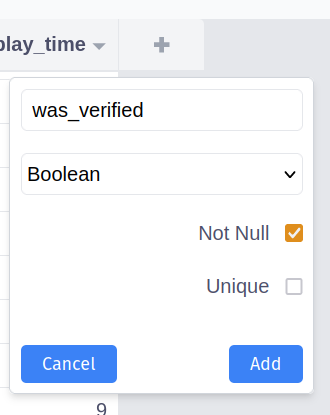
- Delete / Rename / Hide (collapse) column
Click on the arrow icon next to the column in “tables” tab:
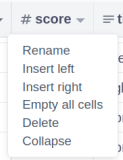 In the case of the “Collapse” option, the process can be reversed by clicking the “Expand” option which appears in it's place.
In the case of the “Collapse” option, the process can be reversed by clicking the “Expand” option which appears in it's place. - Set all entries of column to the default value
Click on the arrow icon next to the column in the “tables” tab and then choose “Empty all cells” (in the case of columns which can be NULL) or “Default all cells” (in the case of NOT NULL columns):
- Reorder columns
The order of a table's columns can be changed by dragging and dropping the two sets of dots at the top of a column in the “tables” tab:
- Delete an arbitrary set of rows
Rows under a table in the “tables” view can be selected by checking the box on their left:
 Alternatively, all rows within a table can be selected by checking the box at top-left corner of the table:
Alternatively, all rows within a table can be selected by checking the box at top-left corner of the table:
 The aforementioned checkboxes can be unchecked to unselect the rows in question. Once at least one row is selected, the “delete” icon at the top-left corner of the table can be clicked to delete the selected rows.
The aforementioned checkboxes can be unchecked to unselect the rows in question. Once at least one row is selected, the “delete” icon at the top-left corner of the table can be clicked to delete the selected rows. - Create a row
Rows can be created by clicking the “+” button at the bottom of their table:

- Edit a cell
Editing a cell is as simple as clicking on it and then typing it's new value!
Certain types offer specialized inputs. For example, colors can be chosen using a color picker:
SQL API Usage
The SQL API is only available in the Enterprise Edition.
curl \
--data '{ "query": "select name, height_in_cm from characters" }' \
--header 'Content-Type: application/json' \
http://localhost:4185/dbs/avatar_characters/sql
yields:
{
"rows": [
{ "name": "Aang", "height_in_cm": 137 },
{ "name": "Katara", "height_in_cm": 145 }
],
"runtime": {
"real": 0.0,
"user": 0.000214,
"sys": 0.00009
}
}
Useful SQL Snippets
Basics
- Rename a column
ALTER TABLE table_name RENAME COLUMN current_name TO new_name; - Count lines of text in a column
LENGTH(col) - LENGTH(REPLACE(col, X'0A', '')) + 1 - Check if all values in a group are the same
iif( count(DISTINCT filetype) = 1, filetype, NULL ) - Get ISO 8601 timestamp with millisecond precision
SELECT strftime('%Y-%m-%dT%H:%M:%fZ') - Create table with an automatically set timestamp column
CREATE TABLE "logs" ( "created_utc" TEXT NOT NULL DEFAULT (strftime('%Y-%m-%dT%H:%M:%fZ')), … ) - Select all rows of a table except the first one
SQLite does not allow
OFFSETwithout aLIMITclause. To work around this restriction, simply set theLIMITto-1:SELECT * FROM table_name LIMIT -1 OFFSET 1 - Only update value if it's not
NULLThis is especially useful if you're passing the value from the code calling your SQL query. For example here it only updates the name value (passed in via:name) if it is notNULL.UPDATE users SET name = COALESCE(:name, name) WHERE rowid == 2 - Include example data in an SQL query
You can combine SQLite's CTE (common table expression) with the
VALUESsyntax to create a temporary table that you can then use in a subsequent query:WITH users(name, color, size_cm) AS ( VALUES ('John', 'red', 175), ('Anna', 'green', 168) ) SELECT * FROM users - Delete duplicate rows
DELETE FROM "users" WHERE rowid NOT IN ( SELECT min(rowid) FROM "users" GROUP BY "" ) - Update several specific fields in a column at once
UPDATE "items" SET "color" = CASE rowid WHEN 1 THEN 'red' WHEN 2 THEN 'turqoise' WHEN 3 THEN 'yellow' ENDWHERE rowid IN (1, 2, 3)to the end.
JSON
Extract value from JSON object
SELECT id, userObject->'birthday' FROM users WHERE json_valid(userObject) = TRUEMerge a column of JSON objects Table
changesid json_patch 1 { "a": 1, "b": 2 } 1 { "a": 2 } 2 { "c": 3 } SELECT DISTINCT "key", last_value("value") OVER (PARTITION BY "id" || "key") AS "value" FROM "changes", json_each("changes"."json_patch")Yields:
id key value 1 a 2 1 b 2 2 c 3 To better work with deeply nested objects and arrays, it's recommended to flatten the JSON before inserting it into a cell. E.g. with github.com/hughsk/flat.
Extract a URL from a column and store it in another JSON column <aside> ⚠️ This uses a space character to find the end of the URL. It does not work with other whitespace characters like newlines and tabs.
</aside>
CREATE TABLE notes ( body TEXT, metadata TEXT ); INSERT INTO notes(body, metadata) VALUES ('https://github.com/user/repoA', NULL), ('Check out https://github.com/user/repoB for more information', NULL), ('Where is https://github.com/user/repoC hosted?', '{"size": "S"}'); UPDATE notes SET metadata = json_insert( ifnull(metadata, '{}'), '$.github_url', substr(body, instr(body, 'https://github.com'), CASE WHEN instr(substr(body, instr(body, 'https://github.com')), ' ') == 0 THEN length(substr(body, instr(body, 'https://github.com'))) ELSE instr(substr(body, instr(body, 'https://github.com')), ' ') - 1 END ) ) WHERE body LIKE '%https://github.com%'; SELECT * FROM notes;
Generation
Get a random number between 0 and 1 with 2 decimal places
SELECT ABS(RANDOM() % 1E2) / 1E2Note:
ABS(RANDOM()) % 1E2would cause an uneven distribution.Generate a table with numbers from 1 to 10
WITH RECURSIVE ten(x) AS ( SELECT 1 UNION ALL SELECT x + 1 FROM ten WHERE x < 10 ) SELECT * FROM ten;Generate a table
random_datawith x rows of random entriesCREATE TABLE random_data AS WITH RECURSIVE tmp(n, txt) AS ( SELECT random(), hex(randomblob(10)) UNION ALL SELECT random(), hex(randomblob(10)) FROM tmp LIMIT 1000000 ) SELECT * FROM tmp;Add a “row number” column (starting from 1) Example table
sales:year amount 2021 1348 2022 544 2023 1312 2024 1176 Steps: Use window function
ROW_NUMBER(sqlite.org/windowfunctions)SELECT ROW_NUMBER() OVER (ORDER BY "year") AS row_number, * FROM "sales"Result:
row_number year amount 1 2021 1348 2 2022 544 3 2023 1312 4 2024 1176 Set a random date time between
2000-01-01and2024-01-20for first 10 itemsUPDATE "items" SET "datetime" = datetime( (julianday('2024-01-20') - julianday('2000-01-01')) * (SELECT ABS(RANDOM() % 1E4) / 1E4) + julianday('2000-01-01') ) WHERE rowid IN ( SELECT rowid FROM "items" LIMIT 10 )
Advanced
Get all possible sub-paths for a column with paths / urls E.g for this table:
name path image.png a/b story.txt c/d/e You would receive following result:
sub_path a a/b c c/d c/d/e WITH RECURSIVE Paths(segment, remaining) AS ( SELECT DISTINCT '', path || '/' FROM files UNION ALL SELECT DISTINCT CASE WHEN segment = '' THEN SUBSTR(remaining, 0, INSTR(remaining, '/')) ELSE segment || '/' || SUBSTR(remaining, 0, INSTR(remaining, '/')) END, SUBSTR(remaining, INSTR(remaining, '/') + 1) FROM Paths WHERE INSTR(remaining, '/') > 0 ) SELECT DISTINCT segment AS sub_path FROM Paths WHERE segment != ''Split a multiline cell into one line per row
WITH RECURSIVE split(id, csv_line, rest) AS ( SELECT id, '', csv || x'0a' FROM csvs UNION ALL SELECT id, substr(rest, 0, instr(rest, x'0a')), substr(rest, instr(rest, x'0a') + 1) FROM split WHERE rest != '' ) SELECT id, csv_line FROM split WHERE csv_line != '';Get the last
NOT NULLvalue in a groupCREATE TABLE test(id, val); INSERT INTO test(id, val) VALUES ('a', NULL), ('a', 123), ('a', 456), ('a', NULL), ('b', 789), ('b', 12), ('b', NULL); SELECT id, val FROM ( SELECT id, val, ROW_NUMBER() OVER (PARTITION BY id ORDER BY ROWID DESC) AS row_number FROM test WHERE val IS NOT NULL ) WHERE row_number = 1;Or with an additional aggregate function:
SELECT * FROM ( SELECT id, FIRST_VALUE(val) OVER (PARTITION BY id ORDER BY ROWID DESC) AS row_number FROM test WHERE val IS NOT NULL ) GROUP BY id;Or only with an aggregate function instead of a window function:
WITH test_grouped(id, val_array) AS ( SELECT id, json_group_array(val) FILTER (WHERE val IS NOT NULL) FROM test GROUP BY id ) SELECT id, val_array ->> (json_array_length(val_array) - 1) AS val FROM test_grouped;yields
id val a 456 b 12 Automatically set a random id after inserting a row
CREATE TRIGGER insert_random_id_after_insert_users AFTER INSERT ON users BEGIN UPDATE users -- 32 hex characters long random id SET random_id = lower(hex(randomblob(16))) WHERE rowid == NEW.rowid; ENDIf it should be possible to set the random ID during insert, check if
NEW.random_idis empty before overwriting it.Convert table of cumulative values to delta values Example table
sales:year total_amount 2021 1348 2022 1544 2023 1612 2024 1876 Steps:
SELECTprevious row withLAG(sqlite.org/windowfunctions)- As we can't calculate a delta amount for the first year, we must omit it from the result table. SQLite requires a
LIMITclause when usingOFFSET. To work around this limitation, we can set theLIMITto-1.
SELECT "year", "total_amount" - LAG("total_amount", 1, 0) OVER (ORDER BY "year") AS "amount" FROM "sales" LIMIT -1 OFFSET 1Result:
year amount 2022 196 2023 68 2024 264